GPT-3 created quite a buzz when it was first launched a couple of months back for its ability to generate great good amount of text to create a more realistic feel, but it suffered from one particular shortcoming that its simply too big. There has been an increasing move towards creating more light weight implementations in NLP,CV and othe areas for machine learning and artificial intelligence, evident from the fact that most of the papers now along with accuracy also feature inference times for the respective model, a good sign of end use awareness in research.
PET (Pattern Exploiting Training)
Pattern Exploiting training is the technique for fine-tuning of already trained (pretrained models) in NLP, where we generate “weakly-labeled” training data from unsupervised setting, this not only helps in creating a vast quantities of datasets for our end use case, but also helps exploit the large chunks of unlabeled dataset available. The approach is also beneficial in a few-shot learning setting where we don’t have many examples and attributes for the training procedure available to get the model up and running in a specific domain with limited number of data points to map to it.
A good walk through for few shot learning is accessible in the video below:
PET vs Current State of the Art
The paper claims to have fine-tuned an ALBERT Transformer model and achieved an impressive average score of 76.8 on the SuperGLUE benchmark, that compares with the current best score of 71.8 for GPT-3. To top it all off the model only uses a fraction of the parameters as the bulky GPT-3, a very impressive feat. More results from the paper are reproduced below for reference.
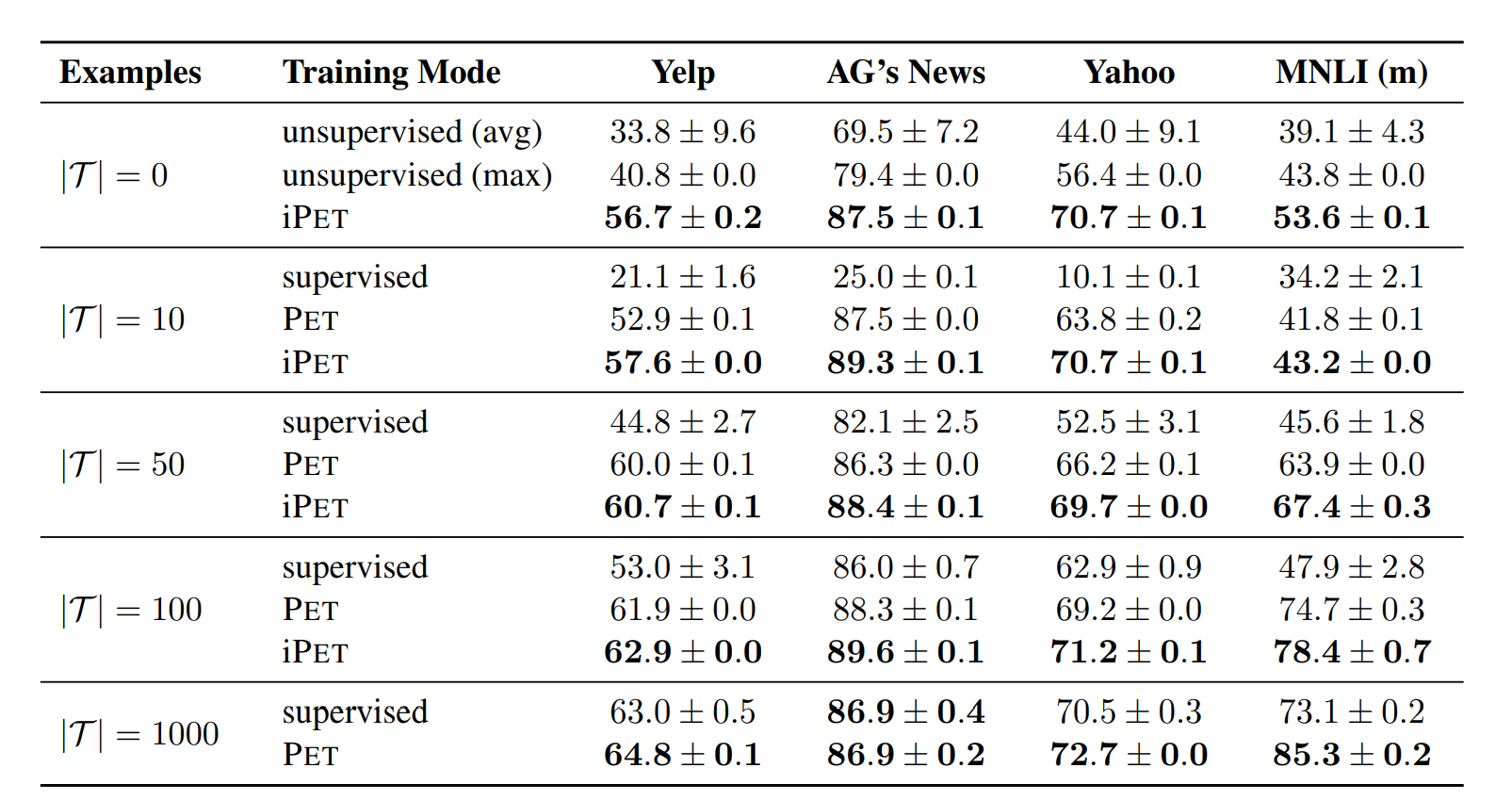
The study shows that we can provide task descriptions to pretrained natural language processing models or language models with the regular approach of supervised learning. The PET method consists of pairs of cloze question patterns and verbalizers that allow the model to leverage the knowledge contained within the existing understanding of the pretrained models for downstream tasks. We ca also finetune the models for all pattern-verbalizer pairs, which can then be used to create large annotated datasets for regular classifiers.
Where the technique really stands out is when there is a very limited amount of data available, in that circumstances PET gives a really large improvement over regular supervised learning.
** Copyright for the title image is with dreamstine